2017 年 9 月 23 日,又拍云 Open Talk NO.36 期活动在北京举行,数人云产品总监作了主题为《高并发微服务平台实践》,以下是分享的实录:
什么要实施微服务化
说到微服务,在和大家讨论时发现最大的问题是,是否要落地实践微服务?因为很多企业并没有达到所需的规模,所以,在准备实践微服务之前需要考量的几个问题是:
- 数据量和业务复杂度有没有达到,若是一个库或一个集群即可搞定,那么建议不要去考虑微服务的问题,大型企业有很多数据库集群去支撑业务,此时,才应该去考虑实践微服务。
- 团队规模,若团队只有十几个人,很多传统WEB三层结构就可以满足需求也无需去考虑微服务,除非团队规模达到上百人,拆分成十几二十几个团队,沟通比较困难时去考虑微服务是比较好的。
- 应对大规模流量并发,很多企业将原来系统的业务开了互联网接口就送出去,此时会遇到很多高流量高并发的问题,此时需要考虑是否要转向微服务,因为传统架构很难应对突发性流量问题。
- 是否需求足够的容错容灾,不要认为所有的系统都需求100%可靠,对于很多企业而言,一些系统停机一天或几个小时并不重要,其实并非任何系统都要做高可用,是否需要自动恢复,运维强度等都是需要考虑的问题。
- 功能重复度和维护差错成本,系统规模越大,功能的重复也越高,现在企业里有很多系统,都要进行认证授权,其实可以单独考虑,否则每个系统都要进行一次,而且并不相同。
若以上问题都不存在,建议还是以三层结构的模式,不要给自己挖坑跳不出来,并非所有企业度适合微服务。
问题思考
如果以传统的RPC结果去应对大规模互联网架构,对于一些企业并不适用,很多RPC结构并非为了高吞吐而是为了快速响应,因为很多时候需要前后端的资源一致,不过一些企业有历史包袱,前端接受请求和后端的服务资源不能完全匹配,所以此时,不能用简单的RPC方式去解决。
业界做微服务通常容易忘了比较重要的一件事:服务治理,用SpringCloud或Dubbo多数用的是一个开发框架将客户端和服务端调通,基本上是人为通过服务注册发现的方式找到服务之后再完成调用,一个很大的误区是,认为这就是微服务了。
另外很多企业不希望丢消息,也并不需要很高的快速响应,来了客户请求,宁愿等一下也是可以的,若是这种请求,RPC也并不一定完全适合。
业务逻辑是否需要每次都进行更改,互联网脚骨里面很重要的一点是业务开发一直在持续迭代,但传统企业很难做到,因为有预算资金、业务规划等方面的约束,而且还需要保留之前已经做好的系统。
微服务其实非常复杂,并不是所有的人、企业都可以搞定,入坑之前一定要进行完整的考虑。
企业业务变化及面临问题
业务模式的变化
传统企业容易面临的问题首先是业务模式上的变化,一些企业原有的模式是人和人打完交道后人为在系统进行操作录入而后走相关流程,很多业务模式都是基于这种方式去走,但问题是一些系统在开发时就已经确定了用户的访问规模,并发程度等,若系统是这种条件下,其实一个简单的Tomcat就可以搞定,哪怕用两个或三个,也可以。
但有的企业在这种情景下,搞了一堆小型机,这是比较要命的问题,因此在这种条件下,不要去做微服务,但如果业务开发模式发生改变,要向互联网转型,一些出口要往互联网开,无论是电脑端或移动端,只要往互联网开放,就要去考虑是否需要走互联网机构或微服务架构的问题了。
不要把原有的系统直接放出去,需要在中间环节考虑保护性和吞吐性的问题,这是业务模式的变化,当业务模式没有变换前不要轻易地去改变架构,并不是说微服务要将原来的体系全部推翻,这是不合理的。
业务开发的变化
还有一点是业务开发的变化,之前提过,很多传统企业需要半年或一年的规划,但现在是两周一个迭代上线,一些公司如豆瓣等,一天变三四次都有,所以需要看整体变化规模有多快,若没有这个变化,慢慢做都可以,也不一定需要微服务了。
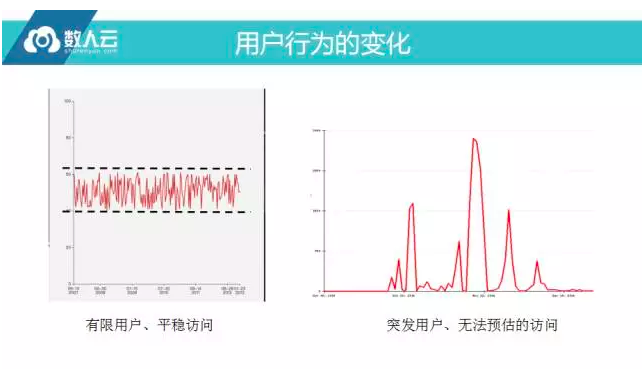
用户行为的变化
最重要的一点是整个用户行为的变化,很多时候,旧系统访问行为是在很窄的范围内,例如,某个普通系统通常美妙十几二十个TPS,我们看到很多文章都提到一天的访问量是几百万次,会觉得组ode很大,但去算一下,若24小时按照每秒是多少次?实际上很少,一天几百万次并不代表访问量很高,另外,互联网模式下,用户规模和访问时间都发生了变化,所以访问的次数分布也会发生很大的变化,特别是将出口开到互联网后,一些业务性的攻击也会来临,这些是很多传统企业无法应对的。
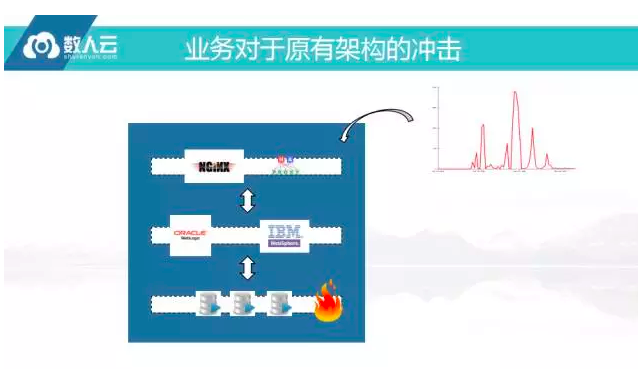
业务对原有架构的冲击
上图是一个简单的传统三层架构,从Nginx或F5这些负载金恒进来,一些大型企业都是买的硬件F5,中间件走的是Weblogic或Websphere,然后再到数据库,只要是这样的架构,即便买来很好的WEB服务系统,但访问模式变了,比较容易挂掉的地方是数据库,曾经有个合作伙伴做了一次店庆促销就是这样,互联网公司做促销都是先做几天预热,然后再去开卖,但在预热阶段就已经挂掉了,因为预热要派卷,数量有限同一时间用户去抢卷,并发量就会突增,这是传统架构比较难处理的地方。

对运维造成的冲击
给运维带来比较大的冲击是:曾经运维管理都是有特定的时间段,但现在需要24小时全天候值守,因此带来的问题是在线升级,传统的运维方式是停机、换包、改配置、重新上线,发现问题后需要重新下线反复上一个循环,现在需要全部在线滚动升级、灰度测试等,另外一个给团队带来的冲击是一些公司依赖于外包,之前我们的客户有很多情况是一个供应商拿着SpringCloud做开发,另外一个拿着Dubbo做开发,最后运维不知道该如何去统一运营,因为两种模式不一样,最后出维内托的时候抓包对包都不知道如何去做。
现在越来越多的公司要求在大的层面统一基础框架也是这个原因。
业界可行的方式
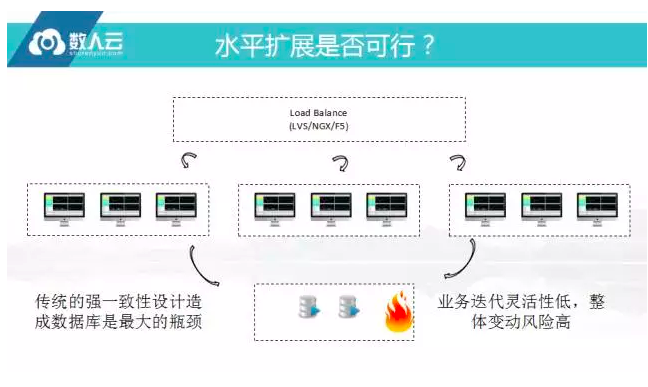
水平扩展是否可行
业界很多容器公司都说可以帮助应对大规模的攻击,其实主要就做了一件事:做水平扩展。Weblogic、Websphere打包方进容器,需要时就扩展,但扩展的越多,死的越快,因为数据库的强一致性依赖,前面接受更多请求数据库更加顶不住,所以在互联网架构下,任何一个公司都不敢直接将数据库强关联的系统对外暴露出去,所以去IOE的概念是把数据库用的越来越弱,在互联网架构里数据库设计的几个范式是要被打破掉的,互联网机构里面是有很大的冗余度,例如前后端都有用户信息,另外就是这种架构下业务是一个整体性,变动起来会很麻烦。
微服务体系
微服务体系
说起微服务,上图是从Microservice.io截过来的,核心的概念是将系统拆分,每个组件都有自己的库,只要将库拆了,库与库之间可能要做相关的一致性同步处理,限于时间问题,今天不做扩展。
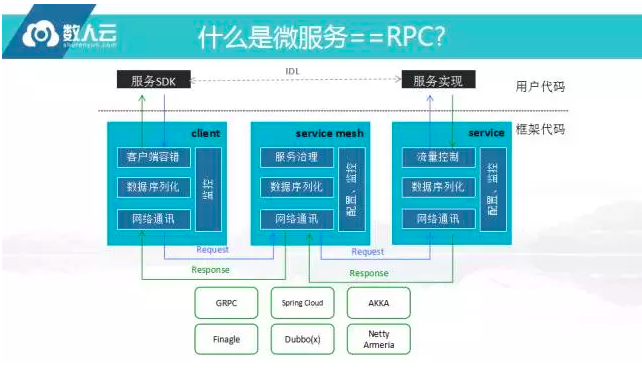
微服务与RPC
SpringCloud 也好,Dubbo 也好,实际上只有 Client 和 Service 两层架构,中间的 Service Mesh 是由 Google 和 IBM 推出的最近比较流行的一个概念,实际上已经有很多互联网公司已经在应用这个概念,它们只是将其抽出作为独立的概念,然后推到了CNCF,比较热门开源的有Istio、Linkerd等。
原来Client到Service端的微服务架构有个较大的问题是将很多的服务治理放到客户端,客户端要做服务治理升级,所有的客户端都需要进行升级,带来的运维复杂度和错误率方面提升,所以Service Mesh核心思想是将很多服务治理抽到中间去做,因此微服务治理越来越多做中间化处理,并不是在客户端和服务端做治理,现在这个概念比较流行,但也暂时不去做扩展。
微服务架构是否等于做RPC架构?这是一个值得讨论的问题。
微服务是一个体系
需要注意的是,微服务是一个体系,这也是为什么前文和大家说不要过多地去考虑微服务的原因,因为很难有公司能自主构建出如此庞大的体系,很多大型的互联网公司都要花费两到三年的时间才能将整个体系构建的比较完整,让业务开展顺畅里面有太多的东西需要去做,虽然通常只看到一个开发框架和服务注册和发现,但后面有很多的东西实际上都没有去做。
微服务后的开发方式转变
微服务后整个开发模式会发生变化,不要认为微服务只是架构上的变化,这是一个很大的误区,微服务进来以后,不单单只是架构上的变化,更多地是组织和流程都发生了改变,CI/CD和DevOps最近两年比较火其实和微服务有很大的关系,这个概念已经有近十年的时间了, 但很多事情都没有用,道了微服务才去考虑这个问题,因为服务数量持续增大痛点才会出现,团队的构建不像以前那种传统的有开发部门、运维部门。测试部门等,现在越多倾向多功能团队的原因就是因为需要快速迭代、测试开发、以及产品、运营作为一个整体团队来做业务开发。
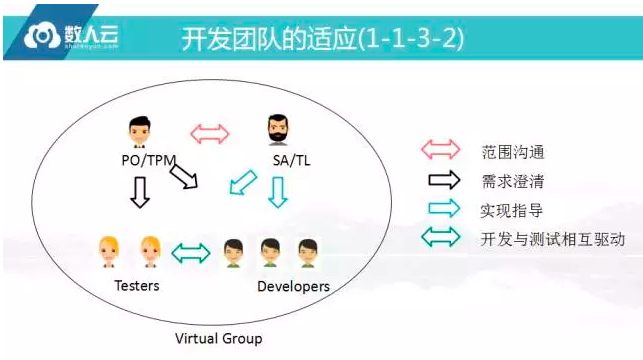
开发团队的适应
上图是团队混搭的模式,一定要做到全功能集合,不可能再去做某个只能划分,这对很多公司是一个挑战,因为这样的设计,不知道公司部门领导什么设置,是设成开发部去领导还是测试部去领导,很多公司不愿改变跟这个也有一定的关系。
传统企业微服务如何起步
前面讲得比较传统,阿里提的Dubbo有5年以上了,体系都比较大,虽然开发模式比较简单,但整体体系非常庞大的后果是迭代速度不一定完全适合中小型企业,因为应对场景不同,希望在微服务理念下能构建一个更小的体系,去应对吞吐这个主流的场景,特别是抢红包或者一些优惠券的场景,而不希望去用一个大的完整的体系,因为无法快速构建出来。
需要将架构构建的更简单一些,不需要太多的东西,架构上面前端没有变化是F5或其他的软LB的方式,从前台、中台、后台的概念来说,前台基本用Tomcat去顶,这个没有太好的方式,因为大家都知道,每一个需求对于Java体系来说,一个请求就是一个线程,所以要支撑足够的并发和吞吐,就要有足够的线程,所以只能用更多的Tomcat去顶这个线程数,如果是容器化的方法,就打开足够多的Tomcat容器实例即可,所以容器很多适合大家用的就是它这一点,快速开足够多的实例数。
但不可能将所有的流量如RPC那样直接传到到后端,因传统系统是顶不住的,一些企业很难去改造传统的业务系统,比如下面有财务或账务处理等不可能改变,大的互联网企业在进行微服务架构改造时,是一整套系统全部概念的,这是很伤筋动骨的事情,但是没有更好的办法,唯一能够做的就是在中间层加一层消息,好处是不需要前端那么多的实例数,后端可以用更少的实例数,慢慢去消费最后将信息反馈出去,这样可以保护好下面传统的系统,特别是保护好数据库,这也是一个比较容易考虑的架构。
而后,微服务体系里面需要考虑如何做动态的管理,一些监控的体系,然后与容器做结合,将操作流程做的更简单,所以将架构简单化时会这样去考虑。
微服务支持高并发平台的愿景
实际上需要构建的是这样的一个系统:将开发做的简单一点,有几个接口杰克,大家用SpringCloud的目标其实只是认为那是比较好开发的框架, 不需要考虑很多通信上的问题。另外可以做到高可用,支持更多的并发,同事是一个平台做统一配置、监控和管理,尽可能做高吞吐数据尽可能地不丢弃并且能跟容器做结合从而轻松运维。
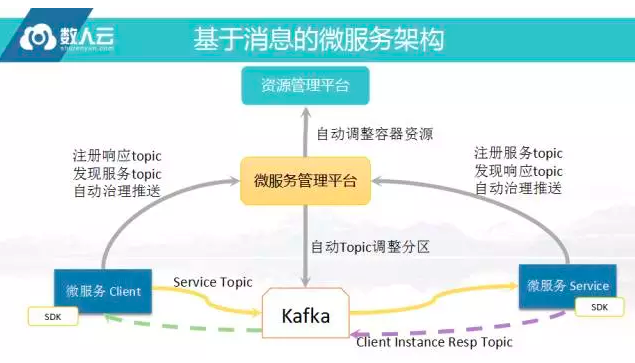
基于消息的微服务架构
我们将这个系统构建出来,实际框图就比较简单了,中间需要一个消息队列,需要一个Kafka、它可以去顶高吞吐的事情,Kafka刚发布了0.1的版本,可以作为所谓的Exactly Once,一个消息只执行一次,客户端和服务端提供服务无注册和服务发现,这和RPC是同样的道理,但是这里的服务发现做了改变,一般的RPC微服务都死将IP和端口注册上去,然后再把IP和端口列表拿回来随机的分发,但是消息微服务不关心IP和端口,关心的只是服务名称对应的消息Topic,发给消息给一个服务,通过服务名称发现服务的Topic,然后发送消息到这个Topic即可。
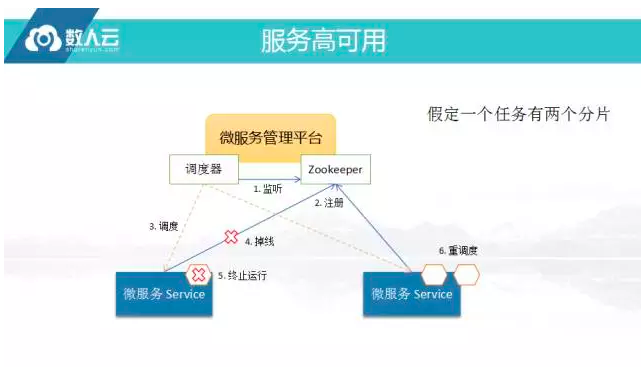
服务高可用
前文提到,高可用是一个很简单的事情,通常做法是自己有调度器,会箭筒Zookeeper节点,所有的服务运行起来时都会注册到Zookeeper的这个节点上,调度器就可知道Zookeeper这个服务已经有两个实例,它会统治这两个实例跑哪些任务。
当掉线时Zookeper上面的这个实例的临时节点会被清掉,这时调度系统就能知道有节点掉线,将它全部迁移到没有掉线的街上,这样比较容易做高可用,高可用的机制大致如此,所以想做高可用,就需要引用一个协调的集群如Zookeeper、Etcd等来做。
动态治理控制
另外要做一些动态性的治理,较容易考虑的问题是要不要做多级别的超时,通常一个客户端设定默认超时即可,但客户端调A服务和B服务的超时是不一样的,这样多级别的设置不可能放到配置文件里面去,可以做的事情全部通过统一的平台动态去做,然后实时下发,这也是一个很重要的概念,所有的服务治理都是动态化,配置界面针对客户端调用某一个服务单独去配超时,所有更新会实时生效,因为所有的协调集群都可以做到动态推送。
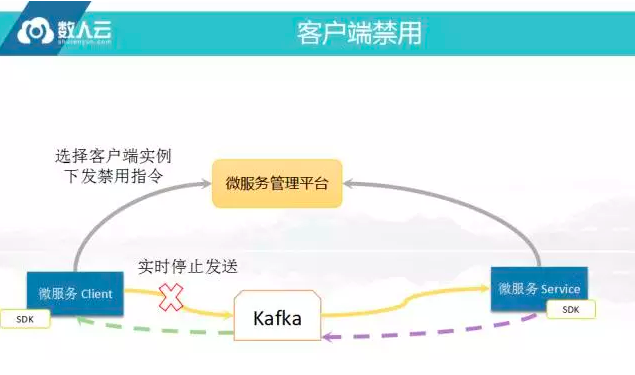
客户端禁用
还可以做服务的禁用管理,很多微服务的客户端将接受的请求直接打到后面将后面的服务冲垮,此时要紧急停某个客户端才可以,早前的反射弧是要找到机器然后想办法登录机器将服务删掉,现在用了框架之后,只要发送一个指令,每次发消息判断哪个指令说是不是禁用,若禁用就不调用服务,所有的消息在客户端报错出去,这样可以实时保护客户端的东西,在整个平台里若开了API,就能做紧急预案,如果发现某个紧急情况,能将客户端所有的请求屏蔽掉,做降级一定要考虑这样的问题,很多公司不知道降级如何做,其实降级就是在什么条件下,将哪些服务关掉,然后能够有首段可以动态将某些服务逐步恢复过来这就是所谓的降级预案的做法。
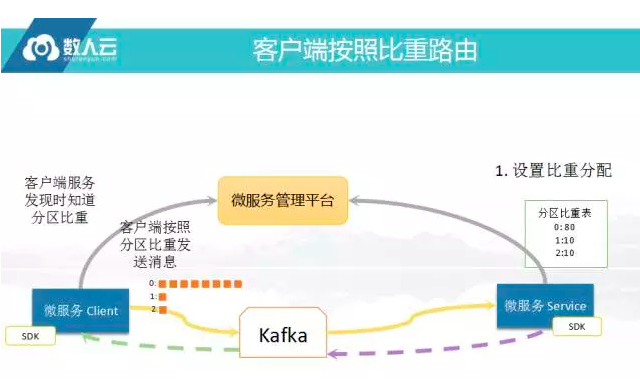
客户端按照比重路由
既然可以管控发送,也可以协调客户端往哪个服务端发送的比例,按照比重去发送,这是比较常见的概念,按比重发送一般在生产环境用的比较少,很多时候做在线压测用,在线流量不一定能够压到某一台机器上,所以需要将所有的流量都导入到那台机器,这也才能知道在线系统能够支撑多大量,因为很多开发环境单独行压测是很难支撑这个测试。
自身管理Dashboard
做Java要考虑的问题是包依赖的冲突,在架构里将架构依赖和业务依赖脱离开,这是需要考虑的问题。
将很多东西统一在一起,不想搞那么多的事情,就需要做很多的Dashboard,越来越重要一点是考虑每一做一个业务都要想想业务有多少指标,这些指标是什么样子,然后将指标汇总画图,所以大家做系统一定要考虑这个事情,Dashboard是越来越重要的概念尽管可能会花费一些力气,但当出现问题时能及时发现,若没有就等同于瞎子和聋子。
兼容Prometheus的Metrics
当然自行做是一方面,可能做图形等会比较麻烦,其实很多中后段的同事并不愿意做话题的事,有个更好的方式是按Prometheus的方式将所有的东西都吐出来将所有的指标所有的数据全部吐出去,吐完之后再用Grafana画,可以节约很多事情,所以要梳理好指标,将所有的东西全部吐出去,现在比较好的是Prometheus在整个中小型规模里面比较容易接受,越来越成为一个事实的规范。

服务依赖拓扑
当谈到微服务比较容易谈到的一点是,一定要做APM,但消息量化比较大,需要一一对应日志分析后才能把依赖找出来,这样的复杂度相对高,但用消息做的好处是通过消息配置找到所有服务的依赖,根本不需要做任何的分析就把服务依赖找到了,这样出问题即可很容易发现,所以这种服务依赖比较容易做,但想真正做调用链,将调用链日志找出来就要单独考虑上APM的事情,所以系统到了哪个规模再去考虑其对应的问题,不可能现在没有这个规模就一下将庞大系统搭建起来,因为可能一天下来就是一百多次调用,出问题时找下日志就可以搞定的问题,但上一个APM没有经验那就可能将自己搞死了,所以就是说现在也是这样的方式简单的依赖方式,但做APM这个事情也可以考虑要把扣子留给APM,后面对接到APM即可。
中国人开源APM并不多,现在基本上能看得见的中国人做的APM开源系统就是Skywalking,大家可以搜一下,同时支持SpringCloud和Dubbo,是Opentracing的标准。
系统无侵入性扩展架构
接下来,要考虑怎么做无侵入扩展,若大家用传统的RPC的方式做微服务,如果出现业务的变化都要做什么事情呢?一般都是增加接口重构系统,增加某个环节,但对于很多企业很难的原因是下面有很多的系统都是一个固有系统,不可能扔掉重来,互联网公司喜欢扔掉再重来一次,但是传统企业很难做到,所以考虑用消息做微服务时,能不能够做到可以无侵入插入一些额外的逻辑?
现在都在谈大数据,无论是否有需求,一天十万行数据也要做大数据,都已经到了这个程度,这时玩大数据就需要做大数据的采集,有很多种手段,包括用Java Agent插入,强行插进去代码做也可以,但用消息有一个好处,将不同逻辑的处理模块都挂在消息集群下面,只要把消息都在这些模块中流转一次即可。
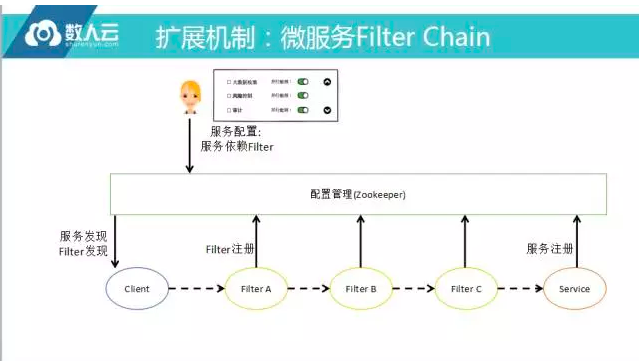
扩展机制:Filter Chain
我们提出一个概念叫FilterChain,意思是每个Filter都被认为是消息服务,消息服务启动时会注册上系统,当注册上来系统就知道这个Filter已经挂载上来,在配置上高速哪个客户端发到服务端时要经过那些Fitler,把这个配置配置好,就把它通知到客户端的SDK里面,开发商还是从客户端发送到服务端,但框架发消息会看这个Filter Chain到底往哪里走,然后将消息按照这个规则往下一层一层传递,传递的过程中也会把下一级的规则一直往下传,最后没有Filter了再发到服务端。
传递的每一个环节是可以并行或串行的,举个例子,如果发到下一个环节只是做数据收集,根本不关心数据包是否合法,这个时候数据采集环节是可以将消息并行直接转到下一个环节处理的,如果要做审计,看看那个包是否合法,实际一定要等那个结果才能往下传,这时要做串行,因此是一个比较好的概念,但要是RPC的方式实现这个理念,还是比较麻烦的。
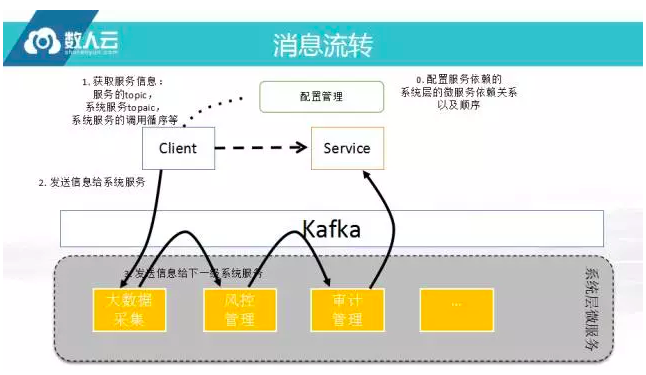
消息流转
消息流转是比较简单的,首先配置怎么做这个事情,剩下的事情SDK根据Filter Chain的顺序一层层往下走即可,代码实现并不复杂。
三种调用模式
既然提到开发上会不会很复杂这个问题,我们的做法是重新封装消息的交互,我们是想做到开发是阻塞应答的模式,下面是消息异步传递,但实际上更好的方式是开发也是异步回调,这样的方式处理消息,会节约很多线程的资源。
更多
当然还可以做更多的事情,包括有统一的平台可以逐渐扩展这些功能,IDC的问题,像是这里面多IDC处理反而更简单,根据配置将消息发送到不同的IDC的Kafka集群即可,无需做特别的处理。
为什么要容器化
另外需要考虑容器化,现在容器化部署能提供更多的灵活性和弹性,简化运维等,一年前谈容器化都在观望,而现在都已经开始做了。
自动调度理念
这个框架还有一个好处,将容器资源调整和消息系统两边一起做伸缩调度,众所周知,如果用Kafka,吞吐量是靠它的分区概念去做的,可以把Topic分很多的区供更多的消费者调用,容器是靠增加实例的方式去做扩容,所以想调度每一个服务扩容时,会同步调整Kafka的分区和容器实例。
问题思考
所以回到最后一个问题,不要认为一做微服务就要通过RPC的方式做,通过消息的方式也可以,另外要更多考虑吞吐的问题,因为把系统放出互联网之后,容易遇到整个数据库顶不住的问题,因为以前的做法通常为了保护下面系统,RPC通常开一个限流,一限流相当于把前端也限住了,所以消息服务也是跟RPC不一样的地方,因为有了消息可以缓冲,消息接受就可以不停,大家知道Kafka的消息都是罗盘的,然后再往下走。
其实消息微服务最好的地方,是可以中间插入逻辑不影响已经开发好的服务,这个对于企业应用是很关键。
