2017 年 09 月 23 日,又拍云 Open Talk NO.36 期活动在北京举行,又拍云平台研发部高级工程师莫红波作了主题为《CI/CD 在又拍云的实践》,以下是分享的实录:
“微服务”这个概念近两年非常热,正在慢慢改变 DevOps 的思路。微服务架构把一个庞大的业务系统拆解开来,每一个组件变得更加独立自治、松耦合。但是,同时也伴随着部署单元粒度越来越小,对交付效率要求也越来越高。一套高效、灵活、高可用的 CI/CD 系统就很关键。所以说 CI/CD 是微服务架构下必不可少的一部分。
这方面有很多的开源项目和工具,比如 Jenkins、Github 默认支持的 Travis 以及本文主要介绍的GitLab CI。
那么“当谈到 GitLab CI 的时候,我们都该聊些什么?”
什么是 GitLab WorkFlow
本章主要讲了 GitLab WorkFlow 从研发到发布交付的一个流程,介绍 CI/CD 所做的事情。
上图来自 GitLab 官方文档,可以让我们更加方便的了解 CI/CD 做了哪些事情。
从左往右看,首先研发人员完成需求提交代码到 GitLab。GitLab 触发一次 Build,构建好服务,然后开始跑单元测试、集成测试。等待测试结果通过后,再由负责该项目的同事进行 CodeReview,灰度发布,正式部署到线上。CI/CD 就是指测试和发布环节,如果能够做到自动化,那么就可以大大加快开发迭代的速度。
如何配置 GitLab Runner 如何把项目接入 CI
GitLab CI 相关术语
在介绍 GitLab 之前,先介绍一下本文主要涉及到术语。
- Job/Build,它是最小的任务单元,只负责一件事情,要么编译,要么测试等;
- Stage,阶段,每一个 Job 都会有一个阶段,一个阶段可以包含多个 Job。阶段是有先后顺序的。通过 stage 可以间接的控制 Job 执行的先后顺序;
- Pipeline,多个 Stage 有顺序的排列就是 Pipeline,流水线;
- GitLab Runner,是实际处理 Job 的,每个 Runner 可以单独配置,Runner 支持多种类型的 Job,同一时间单个 runner 只能处理一个 Job;
- GitLab Multi Runner,是一个 GitLab 的开源项目,用来统一管理 Runner;
- Executor,每个 Runner 都需要指定一个 Executor,来决定 runner最终使用哪个执行器进行处理。
上图是一个典型的 Pipeline,一共有 5 个阶段,Build,Test,Release, Staging, Production,每个阶段里都至少有一个 Job,Test 中有两个 Job。GitLab 会从左往右依次把任务给到 Runner 处理,如果中途有一个任务没有处理成功的话,整个 Pipeline 就会退出。这就是持续集成(CI)、持续发布(CD) 的一个流程。
如何使用 GitLab CI
注册 Runner
GitLab 中提供了两种 Runner 的类型,上图这个界面可以在 GitLab 项目设置页中找到的,一个是特定的 Specific Runner,另一个是共享的 Shared Runner 。特定的 Runner 只能供部分项目使用,而共享的 Runner 是所有 GitLab 中的项目都可以使用的。而这两种类型的 Runner 的注册方式都是一样。
从注册一个特定的 Runner 开始讲,首先安装一个 GitLab Mutli Runner,因为是 Go 语言实现的,所以安装起来会比较简单,直接采用二进制安装即可。第二步正式开始注册,输入 Gitlab 地址、token、描述、标签执行器等。输入上述数据之后 Runner 就注册好了,由于 Multi Runner 支持动态加载配置,所以 Runner 就立即生效了。可以在刚才的界面中看到新增了一个 Runner。有了 Runner,第二步就是如何在项目中增加 .gitlab-ci.yml 的 CI 配置文件。
在项目中增加 .gitlab-ci.yml 的 CI 配置文件
上文所示是一个非常简单的 CI 配置文件。定义了两个阶段,一个 test,一个 build,先执行 test 再执行 build,test 阶段有一个 job 叫做 test,执行的指令是 echo skip,但是这个 job 需要跑在带有 opentalk 的这个标签的 runner 上。build 阶段也有一个 job,叫做 build,它会执行 make docker,去构建 docker 镜像并且推送到私有仓库中,这个任务只有当分支中有 tag 提交才会触发,并且需要跑在带有 online docker builder 的 runner 上。写好这样一个 gitlab-ci.yml 后,commit 一下提交到 Gitlab,你就可以看到 CI/CD 页面上图中增加一条正在跑的任务。
接下来看看 GitLab Runner 的内部实现是怎样的?
GitLab Runner 的实现细节
本章主要分析了 GitLab CI 跟 Runner 信息交互的过程。
从上图可以看出 GitLab CI 是这样一个结构,最上面 GitLab 服务,负责托管代码,支配分解 Job。下面几个是 GitLabMultiRunner,由于支持多操作系统环境,所以图 6 中都加了标注,每一个 GitLabMultiRunner 可以配置多个 GitLab Runner,GitLab Runner 直接跟 GitLab 做交互,这一层通信是通过 HTTP 协议实现的,之后也会讲到。另外有些同学可能已经注意到了,图中 GitLab 是部署在公网上的,而 GitLab Runner 则是在 Nat 之下的,这个设计非常友好,不需要把 GitLab Runner 跟 GitLab 部署在一起,GitLab Runner 甚至可以在自己的笔记本上。
当我们看完了 GitLab CI 的整体结构后,再看看 Runner 跟 GitLab 之间的信息交互是怎样的?
Runner 跟 GitLab 之间的信息交互是怎样的?
信息交互分为几个部分,第一个部分是 Runner 注册。
Runner 会向 GitLab 发送一个注册请求,请求内容中包含 token、 tag 等重要信息,这些其实都是之前配置的时候需要填写的, GitLab 接收一个注册请求之后就会返回一个 token 给 Runner,Runner 之后的请求中都会带上这个 token。
在收到 GitLab 注册成功的消息之后,Runner 就会不停的向 GitLab 请求 Job,时间间隔是 3s。可以看到请求中的 token 已经改成注册时 GitLab 返回的 token 了。
这时会有两种情况:
第一种是没有任务,GitLab 返回 204 No Content;
第二种情况是有任务,GitLab 会把任务信息返回回来,包括任务的 token,job_info,git_info,runner_info 等等。Runner 在接收到 Job 之后,就会向 GitLab 发送一个确认请求,同时更新任务的状态。发送完这个请求,Runner 就开始正式跑任务了。Runner 会定时的发送输出的中间数据,通过向 GitLab 发 Patch 请求的方式。
等任务处理完后,Runner 会发送最终结果、状态、日志等。
最后总结下,第一个注册 Runner,注册成功后 3s 定时请求 Job,接收到 Job 之后发送确认请求,然后开始运行任务,定时把中间结果输出给 GitLab,等任务处理完了,把结果发送给 GitLab。上述内容就是 Runner 跟 GitLab 之间的信息交互流程。
现在 Runner 已经从 GitLab 获取到了任务,下一步 Runner 是怎么做的呢,Executor 又是怎么实现?
Executor
本章主要讲了在Runner 在接收到任务之后,会调用 Executor,Executor 是怎么实现的,重点介绍 Docker Executor 的实现细节
其实 Runner 会去调用对应的 executor,由 executor 来完成接下去的工作。
下图是从 GitLabMutliRunner 项目中截取的一部分代码,基本可以说明 executor 的流程。
第一步:Prepair,做准备工作;
第二步:拉取代码,根据 Job 里的 git_info 字段,Runner 去 GitLab 仓库拉取代码;
第三步:还原缓存,这些缓存是上一次构建留下的;
第四步:下载 artifacts,这是前一个阶段的产生的中间结果;
第五步:执行用户定义的脚本,这里指的是 before_scripts 跟 scripts 两部分;
第六步:执行 after_scripts;
第七步:保存缓存打包 artifacts 等;
第八步:上传 artifacts 供下一阶段使用。
基于这样一个流程,官方提供了 ssh、shell、docker、docker-ssh、virtualbox、kubernates 等执行器,来应对实际使用中的不同场景,本次分享主要也是从 Docker 跟 Docker-ssh 进行展开的。由于Docker 的隔离性强、秒级别启动容器、轻量、回收方便这些特点非常符合集成测试的要求。
首先,如果要使用 Docker executor,CI 配置文件需要做如下调整:
1.定义 image 字段,该字段指定了本次测试环境使用的 Docker 镜像;
2. services,这个字段定义了本次测试依赖的服务,这里依赖的是 redis 跟 mysql。
Docker executor 的实现
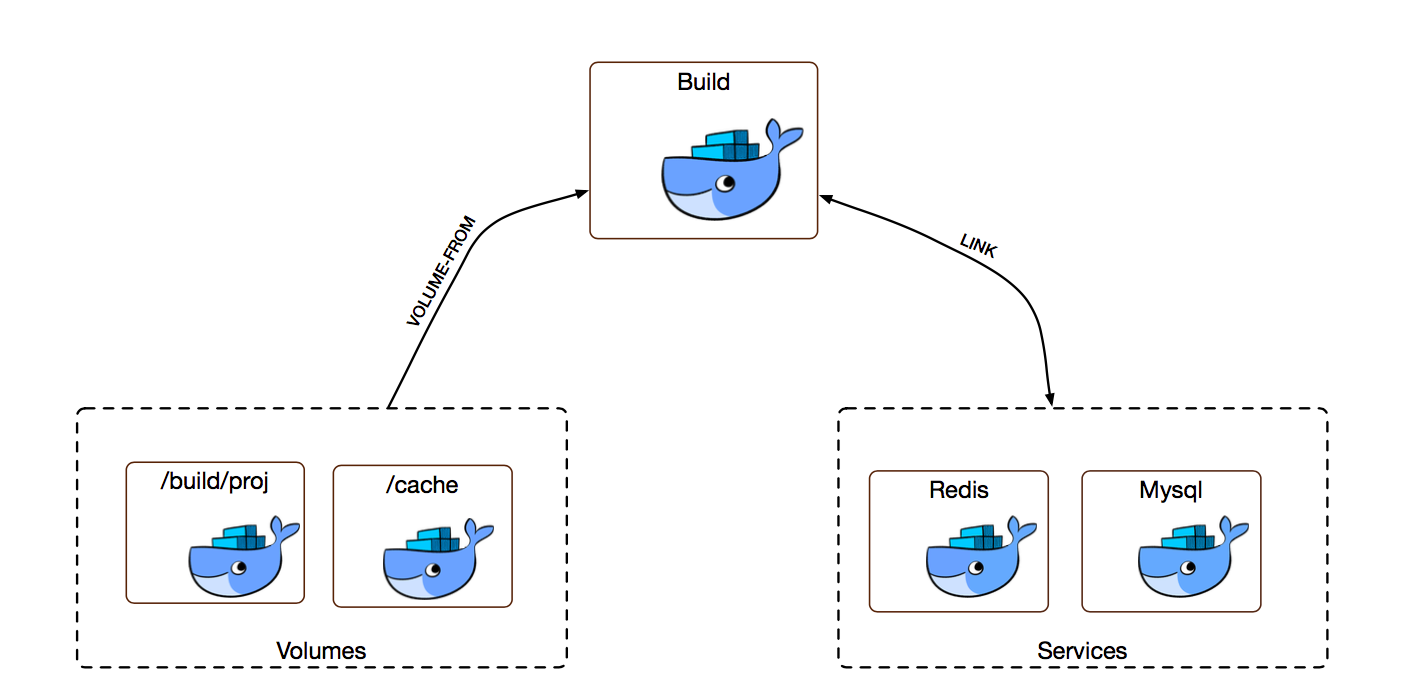
第一步:Prepare,Runner 会先去下载 redis、mysql 等项目依赖的服务,启动映射了目录代码的容器,启动映射了缓存目录的容器。
第二步:GetSource,Runner 会在启动一个 predefine 的容器,通过 volume from 的方式挂载项目代码路径,再通过 predefine 这个容器去拉取代码。由于目录共享,所以 volumes 里的这个容器数据内容也发生了改变。
第三步:执行脚本,runner 会启动一个 build 容器,通过 docker link 的方式把依赖的服务连接起来,通过 docker volume from 的方式加载项目代码以及缓存,然后执行 job 中定义的脚本。
Artifacts
当图片处理项目 Nami 刚接入到 CI 时,是分成 Test 跟 Build 两个阶段处理,Test 阶段需要先编译 Nami,然后启动测试。等测试通过后,执行第二阶段,进行 Docker Build,这时又需要重新再编译依次 Nami,这个过程很费时。后来了解到了 Artifacts 这个功能,可以把这个阶段中产生的文件上传到 GitLab 供下一个阶段来使用,这样以来就不需要二次编译了。
完成优化后,将整个过程拆成了 3 个阶段,第一个阶段进行编译,第二个阶段使用上一个阶段编译好的结果进行测试,第三个阶段使用第一个阶段编译好的二进制做 Docker Build。这样一来,整个过程中只需要做一次编译,大大缩短了构建耗费的时间。
另外上传 GitLab 还有一个好处,安装包可以直接通过网页下载回来。
关于 GitLab CI 的实践经验
C/C++ 编译优化
CDN 项目依赖 Nginx,并且增加了公司定制的逻辑,所以每次测试都需要重新编译 Nginx,但是众所周知编译是十分耗时的。为了解决这个问题,我们引入了 CCACHE。CCACHE 是一个编辑器驱动器,第一次编译时 CCACHE 会缓冲 GCC 的 -E 输出,编译选项以及 O 文件到 $HOME/.ccache 下,第二次编译时尽量利用缓冲,必须时更新缓冲。但是这里会有一个问题,测试跑完之后容器立刻就被回收了,怎么把编译缓存保留到下一次测试呢?
这里就需要用到前面提交的 cache 选项了,cache 选项可以把上一次的缓存目录保留到下一次测试中,供下一次测试使用。但是我们需要对 ccache 做一下配置,修改缓存的路径,指定到 /cache 目录下。
$ ccache —set-config=cache_dir=/cache/.ccache
$ ccache -F 0 && ccache -M 0
Localhost 问题
如果测试中依赖第三方服务的话,docker executor 是通过 docker link 的方式,但是采用这种方式的话,Build 这个容器就无法通过 127.0.0.1 来访问 Redis、Mysql 了。但是研发同学常会把测试环境的配置写成 127.0.0.1,方便本地开发测试。这样一来,接入到 CI 之后就会有不少困扰。针对这个问题,我们给出了两种解决方案。
第一种解决方案是使用别名:在定义 services 的时候,可以定义 alias,来指定该服务的别名,指定好别名之后,Build 容器内就会多一条该别名的解析记录,解析到指定的容器 IP。这种方式下,研发同学只要修改下测试配置就可以把服务跟测试跑起来,不过本地开发的时候,需要增加一条解析记录,把别名解析到 127.0.0.1。
第二种解决方案是端口转发,这种方式更加简单灵活些。拿 redis 举个例子,如果测试中以来了 redis,需要在 build 容器中安装 3proxy 做端口转发,并且把对 6379 端口的请求,都转发到 redis 对应容器的 6379 上去,通过这种方式来解决访问 127.0.0.1:6379。这种方式更加方便,研发同学不需要去修改测试的配置,但是需要在执行测试之前,去启动 3proxy 并配置端口转发规则。
Open Talk 是由又拍云发起的系列主题分享沙龙,秉承又拍云回馈技术、加速在线业务的初衷,从 2015 年开启以来,Open Talk 至今已成功举办 35 期,辐射线上线下近 50,000 技术人群。不管是从某个“主题”出发,横向拓展技术干货分享,还是以一家“企业”为主,纵深挖掘企业的开发、产品、运维体系,Open Talk 秉承“干货不注水”的理念,场场爆满。
